2025.12.04 🚀 - We released AutoCodeBench-V2, built on the original dataset and iteratively refined through top proprietary models and a sandbox to produce 1,000 higher-quality problems! The leaderboard and evaluation tutorial are available in AutoCodeBench-V2!
2025.12.04 📚 - We released AutoCodeInstruct, a large-scale multilingual dataset equipped with golden answers distilled from DeepSeek-V3-0324, and filtered using Qwen2.5-Coder-7B/32B-Instruct to create two versions suitable for RL and SFT training! The dataset is available at autocodeinstruct_v3answer_qwen32b.jsonl and autocodeinstruct_v3answer_qwen7b.jsonl. Experimental details can be found in the paper.
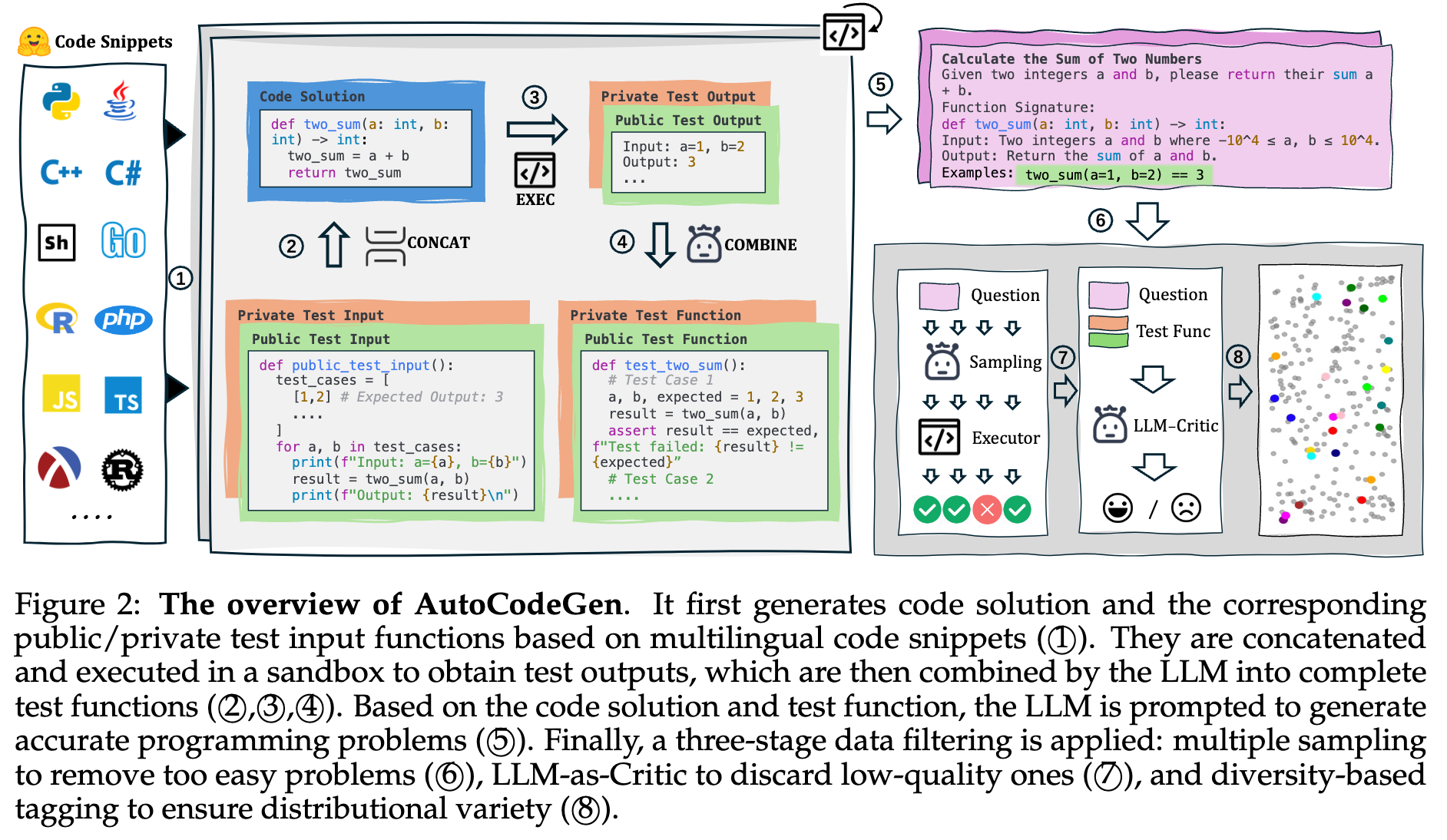
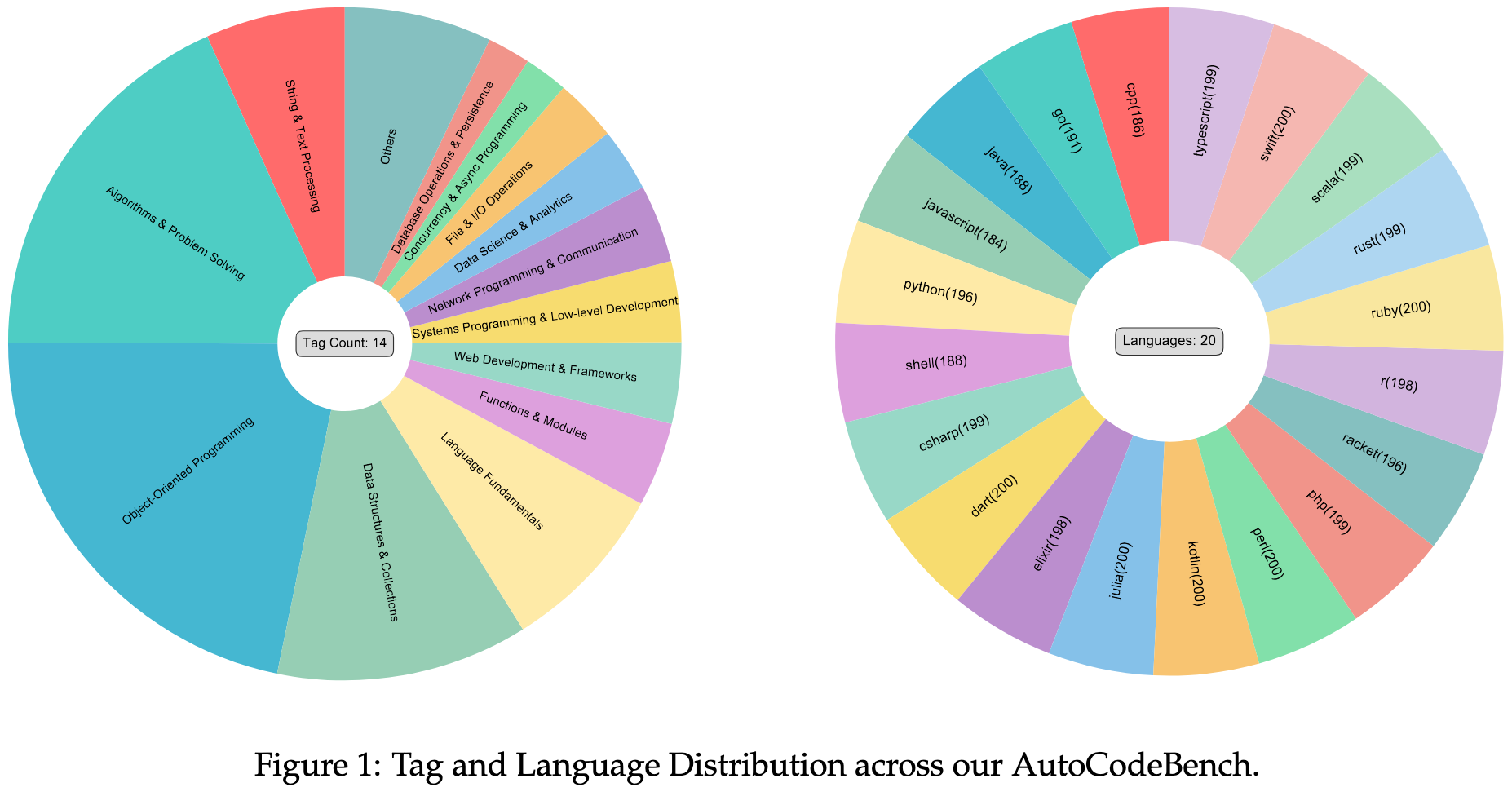
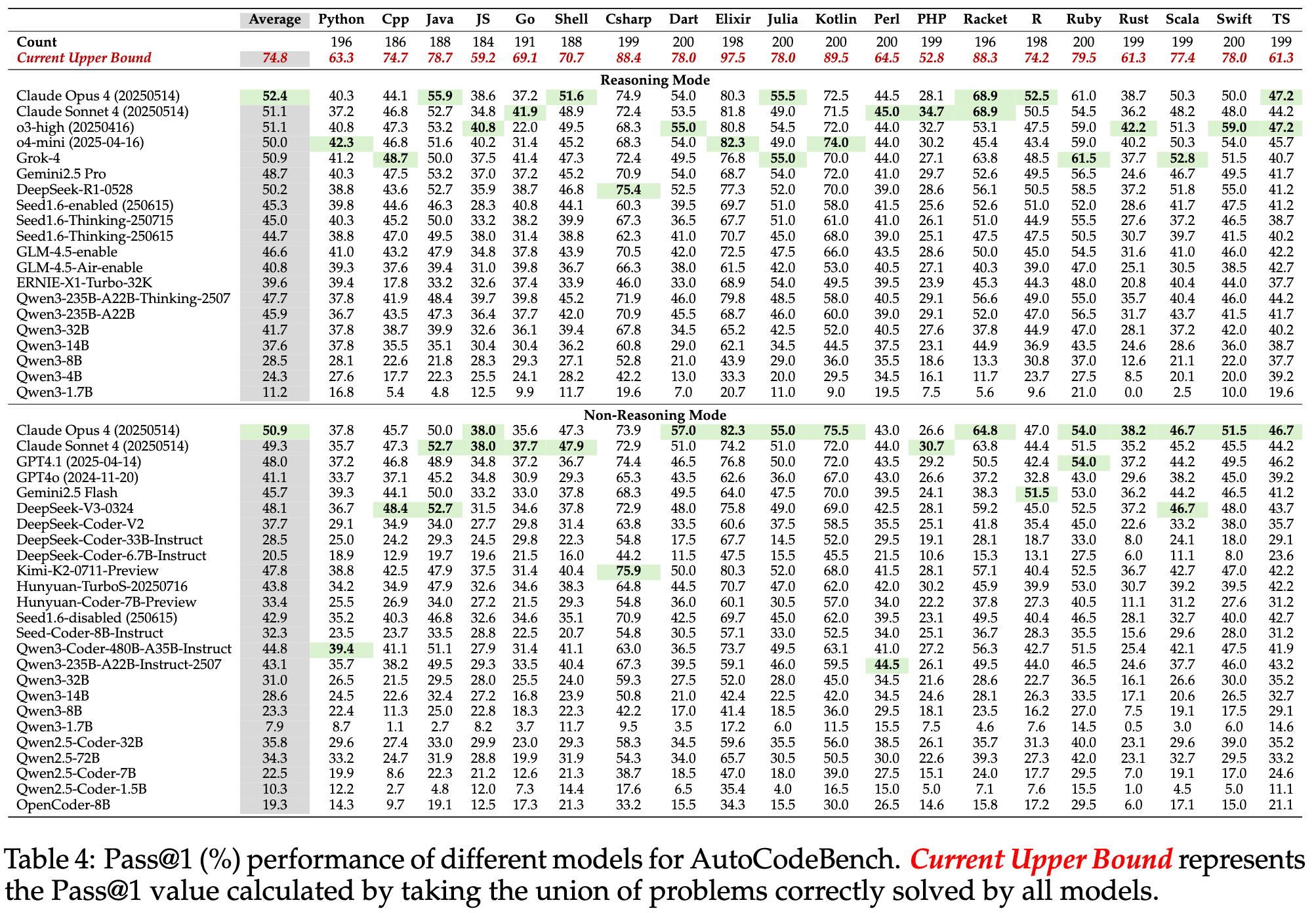
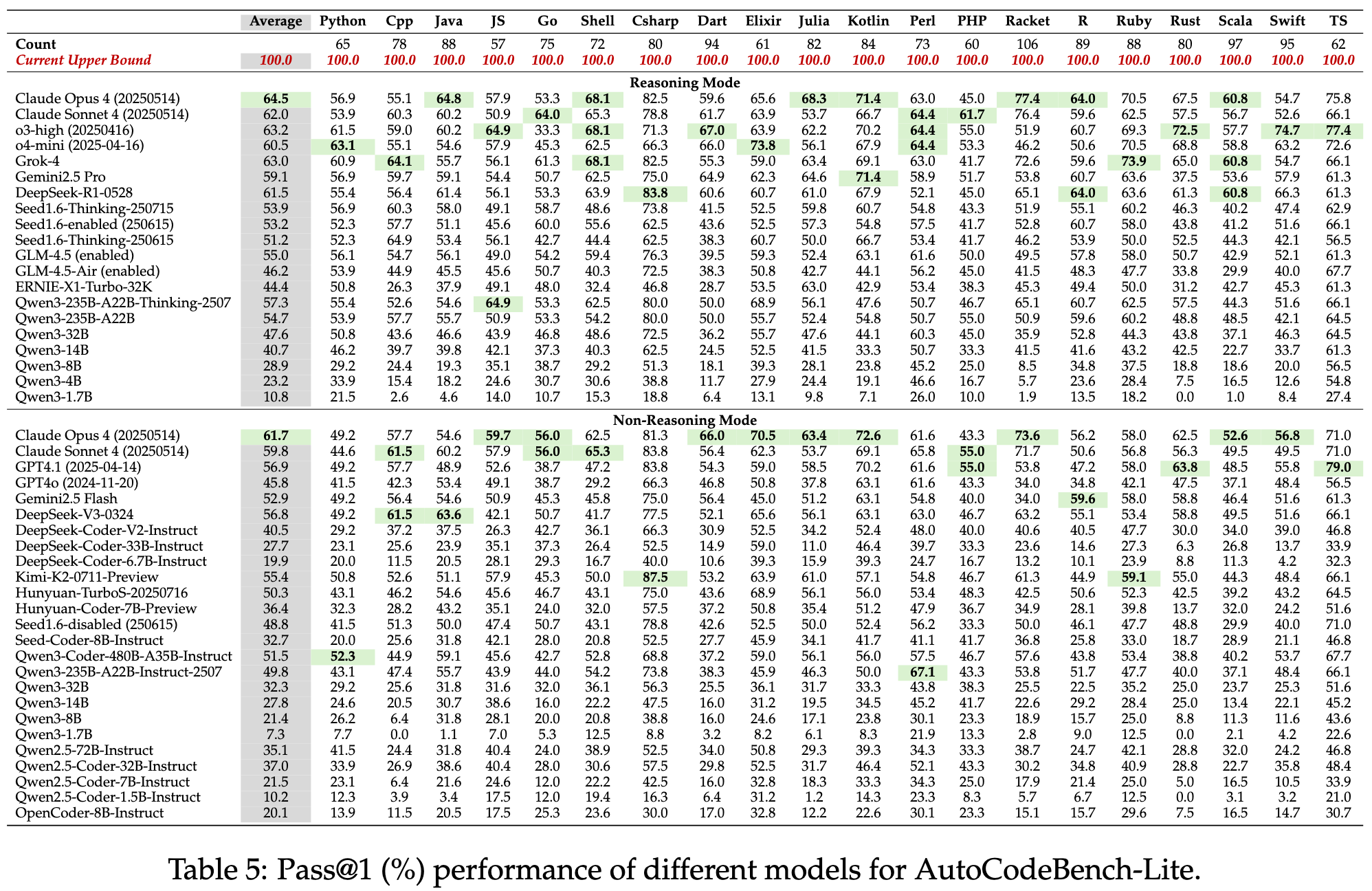
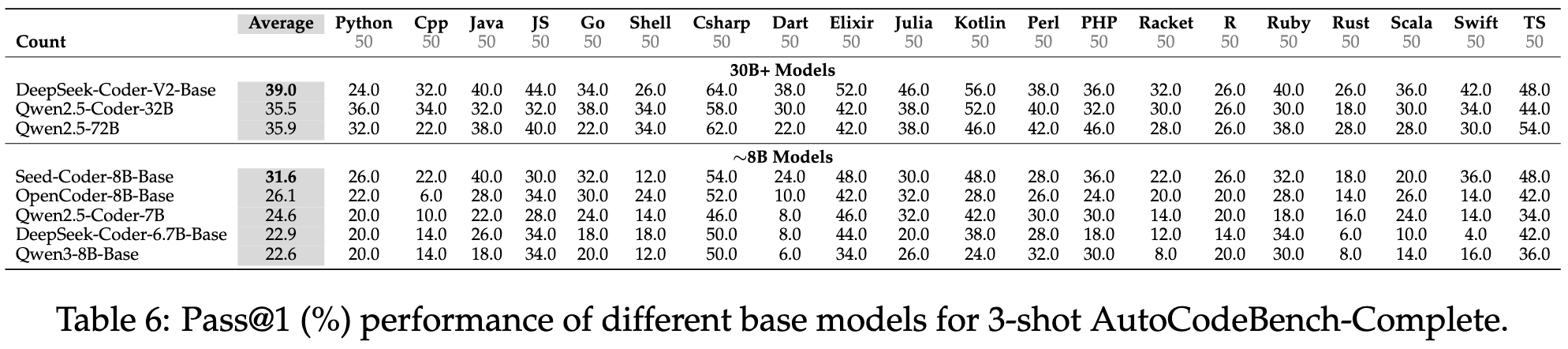
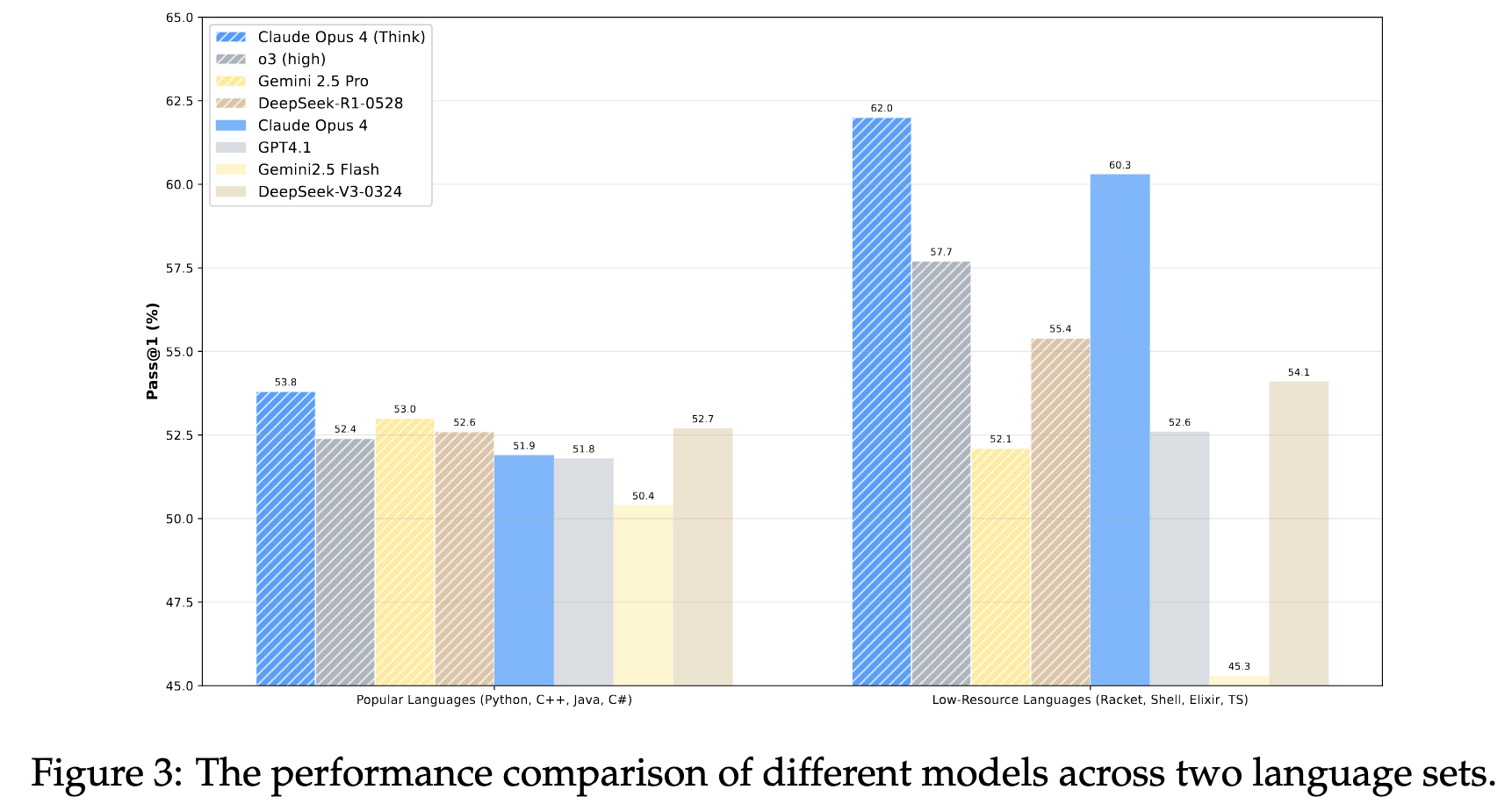
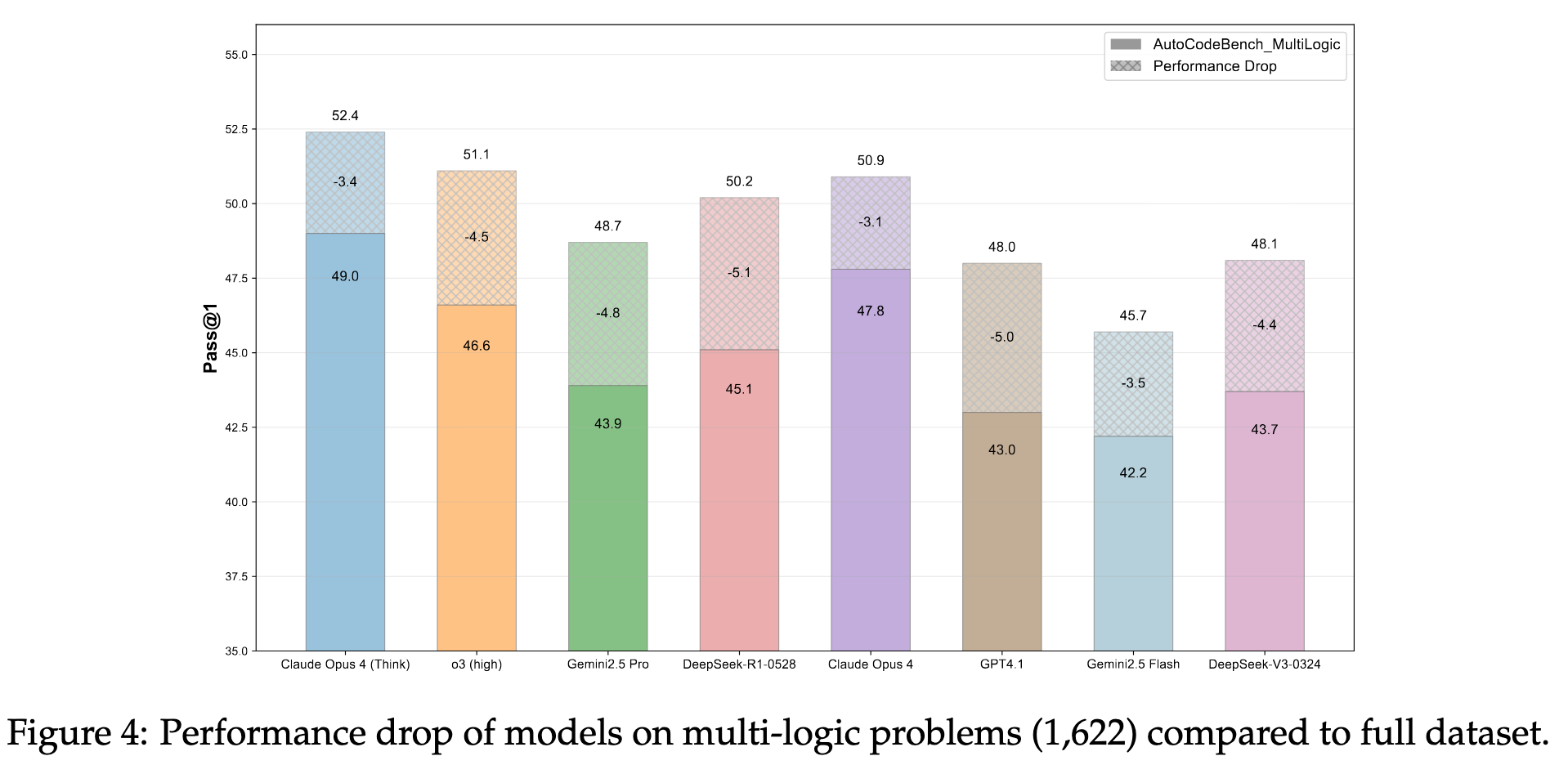
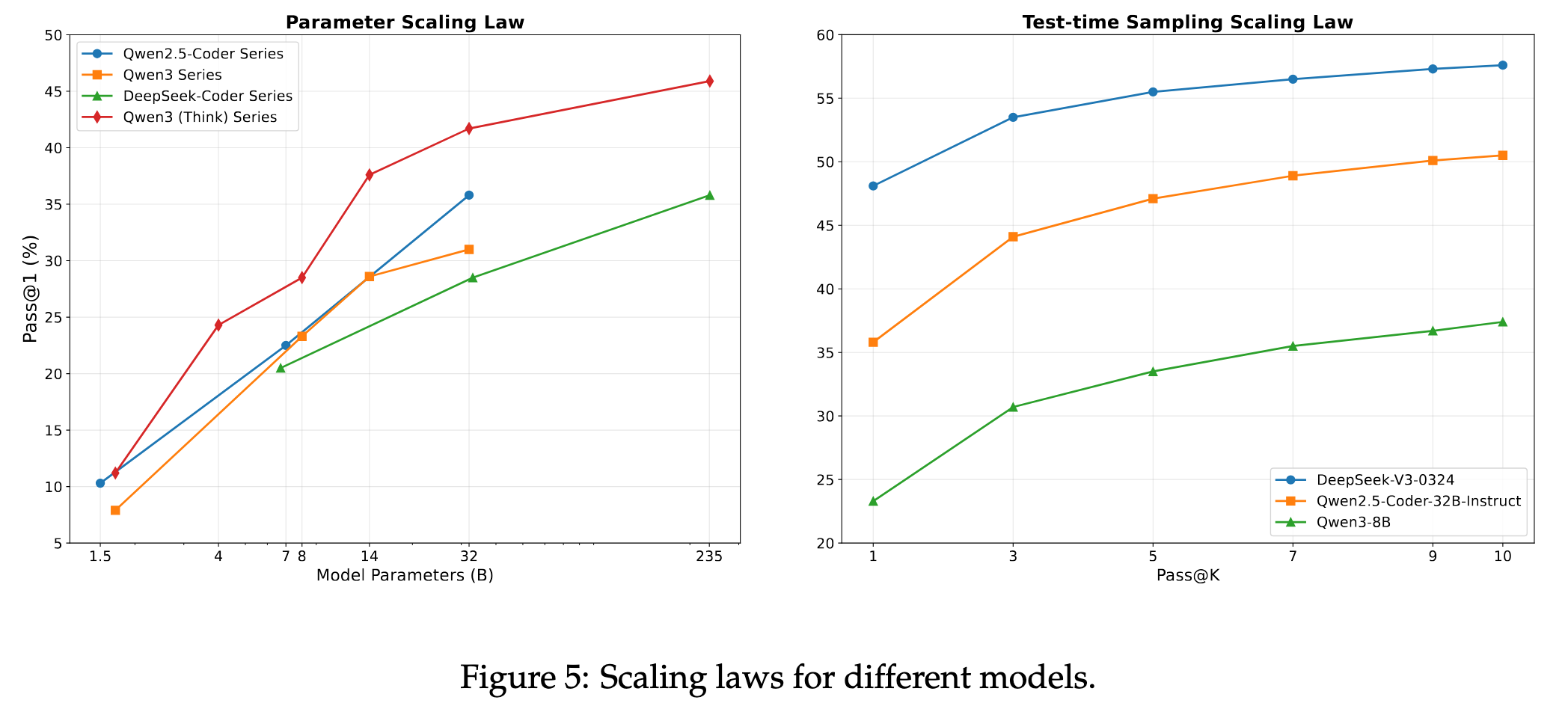
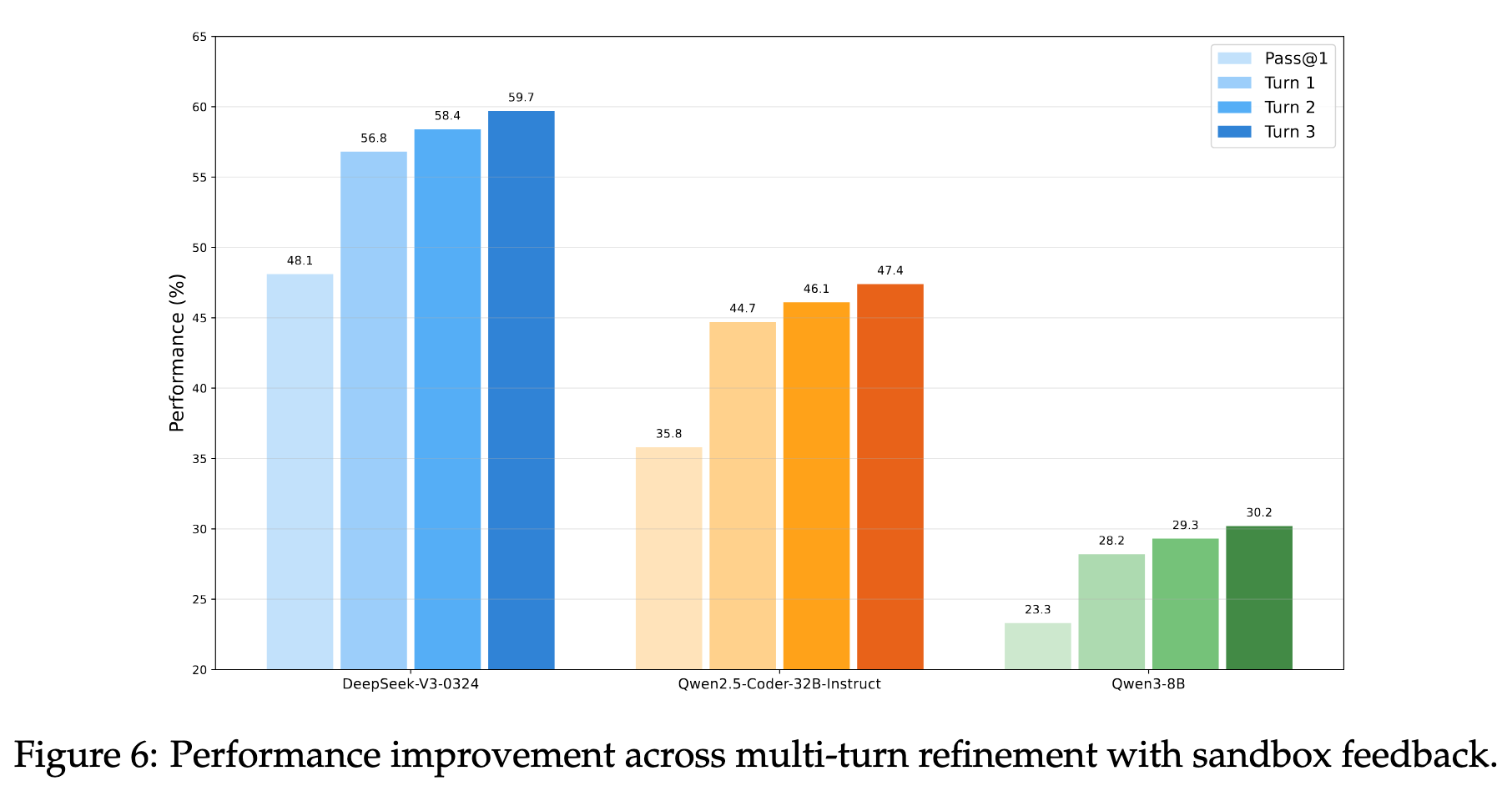
2025.08.15 🎉 - We released AutoCodeGen, AutoCodeBench series, and Multi-lingual Sandbox!
2025.08.13 📄 - We published our arXiv paper!